Introduction
Dramatic and rapid changes to the global economy are required in order to limit climate-related risks for natural and human systems (IPCC, 2018). Governmental interventions are needed to fight climate change and they need strong public support. However, it is difficult to mentally simulate the complex effects of climate change (O’Neill & Hulme, 2009) and people often discount the impact that their actions will have on the future, especially if the consequences are long-term, abstract, and at odds with current behaviors and identities (Marshall, 2015).
- We are developing a tool to help the public understand the consequences of climate change.
- We intend to make people aware of Climate Change in their direct environment by showing them concrete examples.
Currently we are focusing on simulating images of one specific extreme climate event: floods. We are aiming to create a flood simulator which, given a user-entered address, is able to extract a street view image of the surroundings and to alter it to generate a plausible image projecting flood where it is likely to occur.

Recent research has explored the potential of translating numerical climate models into representations that are intuitive and easy to understand, for instance via climate-analog mapping (Fitzpatrick et al., 2019) and by leveraging relevant social group norms (van der Linden, 2015). Other approaches have focused on selecting relevant images to best represent climate change impacts (Sheppard, 2012; Corner & Clarke, 2016) as well as using artistic renderings of possible future landscapes (Giannachi, 2012) and even video games (Angel et al., 2015). However, to our knowledge, our project is the first application of generative models to generate images of future climate change scenarios.
Technical Proposal
We propose to use Style Transfer and especially Unsupervised Image To Image Translation techniques to learn a transformation from a natural image of a house to its flooded version. This technology can leverage the quantity of cheap-to-acquire unannotated images.
Image To Image Translation : A class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs
Style Transfer : Aims to modify the style of an image while preserving its content. CycleGAN (Zhu et al., 2017)
Let and
be images from two different image domains.
represents the non-flooded domain which gathers several type of street-level imagery defined later in the data section and
is the flooded domain composed of images where a part of a single house or building is visible and the street is partially or fully covered by water.

In the unpaired image-to-image translation setting, we are given samples drawn from two marginal distributions : samples of (non-flooded) houses and
samples of flooded houses, without access to the joint distribution
.
From a probability theory viewpoint, the key challenge is to learn the joint distribution while only observing the marginals. Unfortunately, there is an infinite set of joint distributions that correspond to the given marginal distributions (cf coupling theory). Inferring the joint distribution from the marginals is a highly ill-defined problem. Assumptions are required to constrain the structure of the joint distribution, such as those introduced by the authors of CycleGAN.
In our case we are estimating the complex conditional distribution with different image-to-image translation models
, where
is a sample produced by translating
to
.
CycleGAN
CycleGAN is one of the research papers that revolutionized image-to-image translation in an unpaired setting. It has been used as the first proof of concept for this project.

It aims to capture the style from one image collection and to learn how to apply it to the other image collection. There are two main constraints in order to ensure conversion and coherent transformation:
The indistinguishable constraint: The produced output has to be indistinguishable from the samples of the new domain. This is enforced using the GAN Loss Goodfellow et al., 2014 and is applied at the distribution level. In our case, the mapping of the non-flood domain to the flood domain should create images that are indistinguishable from the training images of floods and vice-versa Galenti et al., 2017. But this constraint alone is not enough to map an input image in domain to an output image
with the same semantics. The network could learn to generate realistic images from domain
without preserving the content of the input image. This latter point is tackled by the cycle consistency constraint.
The Cycle-Consistency Constraint aims to regularize the mapping of the two domains in a meaningful way . It can be described as imposing a structural constraint which states that if we translate from one domain to the other and back again we should arrive at where we started. Formally, if we have a translator and another translator
then
and
should be bijections and inverses of each other.
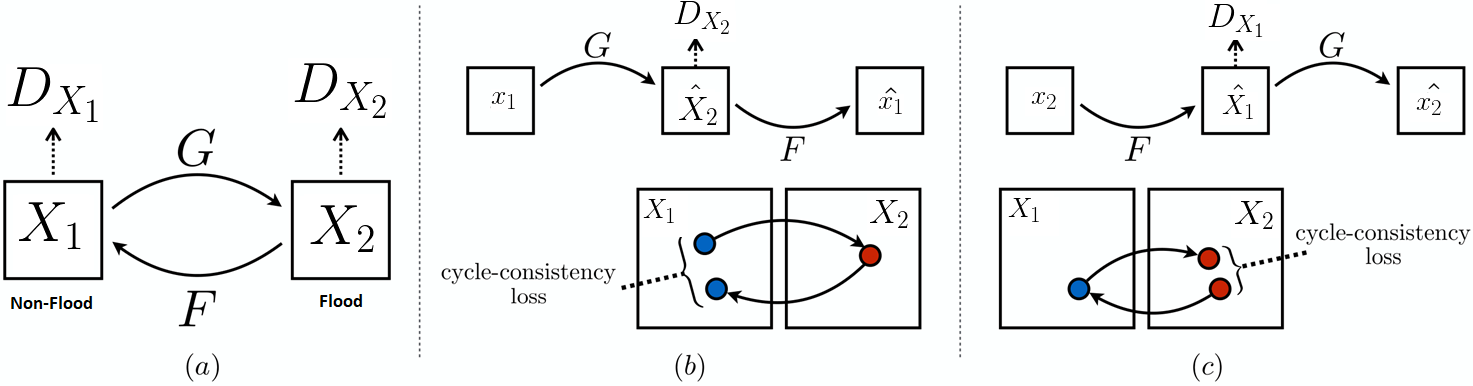
(a) The CycleGAN model contains two mapping functions
and
, and associated adversarial discriminators
and
.
to translate
into outputs indistinguishable from domain
, and vice versa for
.
(b) Forward cycle-consistency loss:
(c) Backward cycle-consistency loss:
Pros and cons: The most advantageous part of this approach is its total lack of supervision, which means that the access to data is cheap (1K images of non-flooded and flooded houses). The major problem is that the style transfer is applied to the entire image.
Initial Results: When the ground is not concrete but grass and vegetation, CycleGAN generates a brown flood of low quality with blur on the edges between houses and grass. The color of the sky changes from blue to grey (probably because of the bias on the training set of flood images).
InstaGAN
The InstaGAN architecture is built on the foundations of CycleGAN. The main idea of their approach is to incorporate instance attributes (and
) to the source
(and the target
) domain to improve the image-to-image translation. They describe their approach as learning joint mappings between attribute-augmented spaces
×
and
×
.
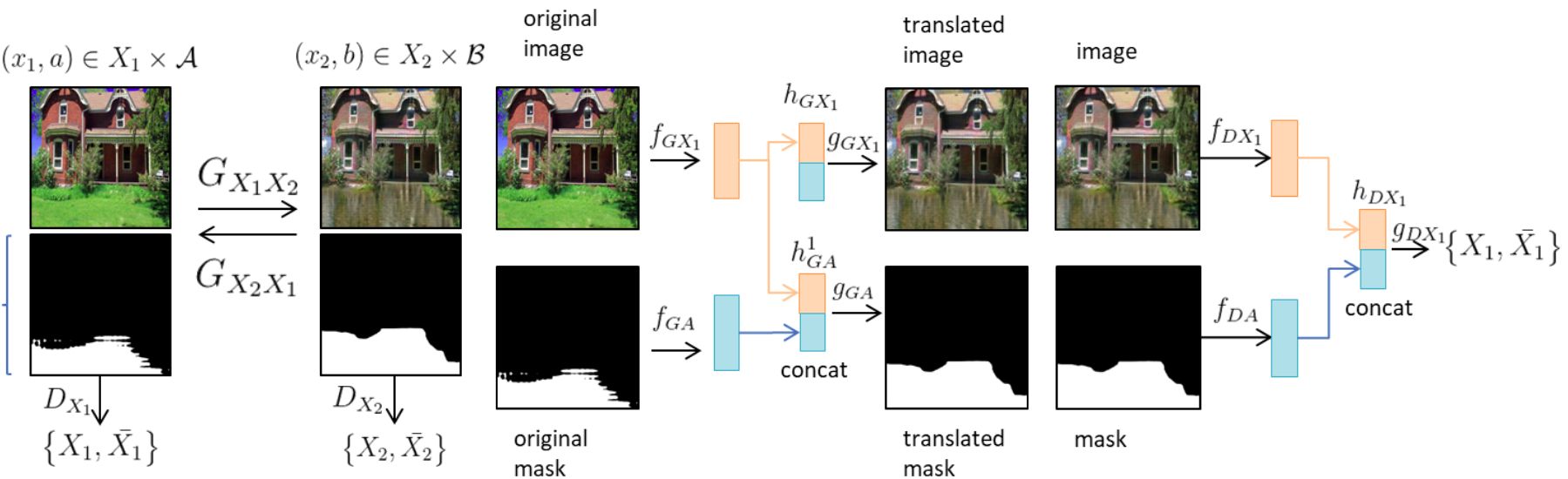
In our setting, the set of instance attributes is reduced to one attribute: a segmentation mask of where-to-flood and for the attribute of
a segmentation mask covering the flood. Each network is designed to encode both an image and a set of masks (in our case a single mask).
The authors explicitly say that any useful information could be incorporated as an attribute and claim that their approach leads to disentangle different instances within the image allowing the generator to perform accurate and detailed translation from one instance to the other.

Pros and cons:. As for CycleGAN InstaGAN doesn't need paired images but requires the knowledge of some attributes, here the masks. Sometimes the model is able to render water in a realistic manner, including reflections and texture. But a major drawback is that, although it's penalized during training, it continues to modify the rest of the image (the unmasked region): colors change, artifacts appear, textures are different and fine details are blurred.
Results: Empirically we find that it works well with grass but not with concrete. Transparency is a big issue with InstaGAN's results on our task, since most of the time we can see the road lanes through the flood. Even in synthetic settings with aligned images InstaGAN generates relatively realistic water texture which remains transparent. We could conclude that it learns to reflect the sky on the water (whatever the color of the sky is), resulting in the fact that sometimes it paints blue on the concrete itself without the accompanying water texture. In our case results quality worsen dramatically out of the training set.
Note: The instances used in the papers are either segmentation mask of animals (e.g. translating sheep to giraffe), or segmentation mask of clothes (e.g. translating pants to skirt). In both cases, I found that theses instances are less diverse than instances from our non-flood to flood translation in the sense that sheep color, shape, texture is less diverse than the examples of flood or street in our dataset.
Generative Image Inpainting
Previous approaches based on modification of CycleGAN does not give us a fine control over the region that should be flooded. Assuming we are able to identify such a region in the image, we would only need to learn how to render water realistically. There are a lot of promising image edition techniques in the GAN literature demonstrating how to perform edition of specific attributes, morphing images or manipulating the semantic. These transformation are often performed on small latent space of generated fake images. However, natural image edition is a lot harder and there is no easy way of manipulating the semantic of natural images.
Image Inpainting is the technique of modifying and restoring a damaged image in a visually plausible way. Given recent advances in the field, it is now possible to guess lost information and replace it with plausible content at real-time speed.

For example, a recent deep-generative model exploiting contextual attention: DeepFill, is able to reconstruct high definition altered images of faces and landscapes at real-time speed. We believe that there is a way of leveraging the network generation capacity and apply its mechanisms to our case. Our experiment consist in biasing DeepFill to reconstruct only region where there is water (without surrounding water). We trained the network with several hundreds images of flood where the water was replaced by a grey mask. At inference we replaced what we defined as the ground with a grey mask. (see results below)

Results: The quality of the result is bad when given large masks. This could be explain by the fact that the architecture is designed to extract information from the context in the image: in the former experiment the network had to draw from a context where water is inexistent. To pursue research in that direction, one may want to give a better context to the network by using example of water texture on the side of the image. Or by increasing the dataset of images where there is water.
Current Approach
Our current approach is built on MUNIT. In the paper, a partially shared latent space assumption is made. It is assumed that images can be disentangled into a content code (domain-invariant) and a style code (domain-dependant). In this assumption, each image is generated from a content latent code
that is shared by both domains, and a style latent code
that is specific to the individual domain.
In other words, a pair of corresponding images from the joint distribution is assumed to be generated by
and
, where
are from some prior distributions and
,
are the underlying generators. Given the former hypothesis, the goal is to learn the underlying generator and encoder functions with neural networks.
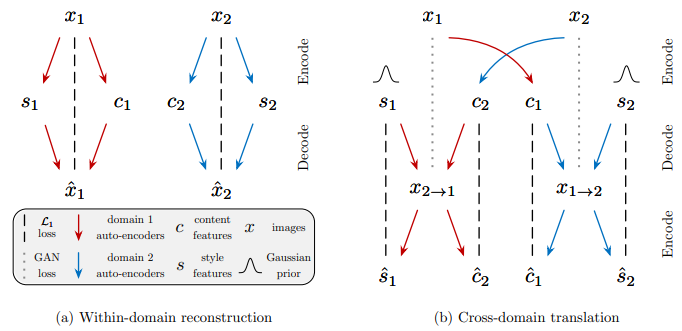
Image-to-image translation is performed by swapping encoder-decoder pairs. For example, to translate a house to a flooded-house
, one may use MUNIT to first extract the content latent code
of the house image that we want to flood and randomly draw a style latent code
from the prior distribution
of flooded-houses and then use
to produce the final output image
(content from
and style from
).
How does it work ?
Huang et al. demonstrated that Instance Normalization is deeply linked to style normalization. Munit transfer the style by modifying the features statistics, de-normalizing in a certain way. Given an input batch , Instance Normalization Layers are used in MUNIT encoders to normalize feature statistics.
Where and
are computed as the mean and standard deviation across spatial dimensions independently for each channel and each sample. Adaptative Instance normalization layers are then used in the decoder to de-normalize the features statistics.
With and
defined as a multi-layer perceptron (MLP), i.e., [
] = [
]=MLP
with
the style. The fact that the de-normalization parameters are inferred with a MLP allow users to generate multiple output from one image.
Modifying the network to fit our purpose:
We questioned and transformed the official MUNIT architecture to fit our purpose.
Because we wanted control over the translation, we removed randomness from the style: the network is then trained to perform style transfer with the style extracted from one image and not sampled from a normal distribution.
After analyzing the feature space of the style, T-SNE plot we decided that sharing the weights between the style encoders could help the network to extract informative features. Since the results were not affected by this ablation we kept it. (See Experiment)
We shrink the architecture to use a single AutoEncoder and concluded that it was either longer to converge or that the transformation was harder to learn since the results were affected negatively. (See Experiment)
Based on the fact that the flooding process is destructive and that there is no reason that the network could reconstruct the road from the flooded version, we implemented a weaker version of the Cycle Consistency Loss where the later is only computed on a specific region of the image. The specific region is defined by a binary mask of where we think the image should be altered. For example a flooded image mapped to a non-flooded house should only be altered in an area close by the one delimited by the water. (In practice there are bias intrinsic to the dataset such as the sky often being gray in a image of flood) (See Experiment)
We trained a classifier to distinguish between flooded and non-flooded images (binary output) then use it when training MUNIT with a Loss on the generator indicating that fake flooded (resp non-flooded) images should be identified as flooded (resp non-flooded) by the classifier. It didn't improve the results we had, like if the flood classifier was a very bad discriminator that the generator could trick easily. (See Experiment)
To push the style encoder towards learning meaningful information, we investigated how to anonymise the representation of the content feature learned by MUNIT encoder. The idea behind is that if the content feature doesn't contains information about the domain it has been encoded, then the style would encode this information. We hence minimized the mutual information between the content feature and the source of the content. To do so we used a Domain-Classifier as in Learning Anonymized Representations with Adversarial Neural Networks
We experiment playing with the training ratio of the Discriminator and the Generator. We empirically found that a factor 5 does improve slightly the convergence speed.
Major Changes: Introducing a Semantic Consistency Loss, we use DeepLab v2 trained on cityscape to infer semantic label, and implemented an additional loss indicating to the generator that every fake image should keep the same Semantic as the source image before translation everywhere except a defined region where we think there should be an alteration. This modification dramatically improved our results. (See Experiment)
We also experimented with DeepLab v2 trained on COCO-Stuff. We thought this version would better suit our problem because it is able to identify water on the road but it turned out that (maybe because of the large number of classes) it didn't constrained much the network as with the previous version. We also tried to merge the classes from coco-stuff to only keep meta-classes that would be similar to cityscapes, it would allow us to keep a small number of classes and leverage the potential of identifying the water. (Impossible with Cityscape classes) (See Results).
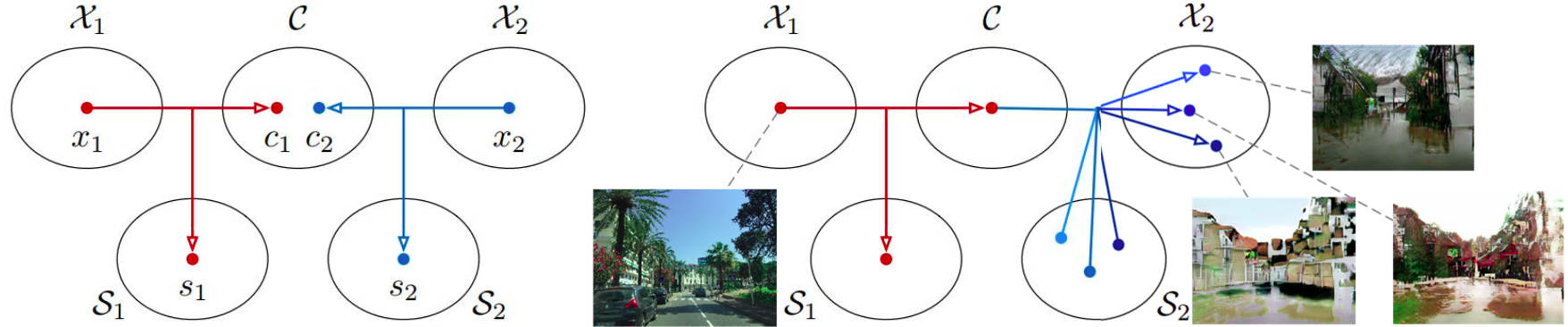
How to leverage simulated data ?
We plan of using a simulated world built by Vahe Vardanyan with the Graphics Engine Unity to simulate different types of houses and streets under flood conditions to help our GAN understand where it should flood.

One main advantage of using synthetic data is that theoretically we would have access to an unlimited amount of pairs. The principal difficulty lies in leveraging those pairs despite the existing discrepancy between the distribution of synthetic and real data.
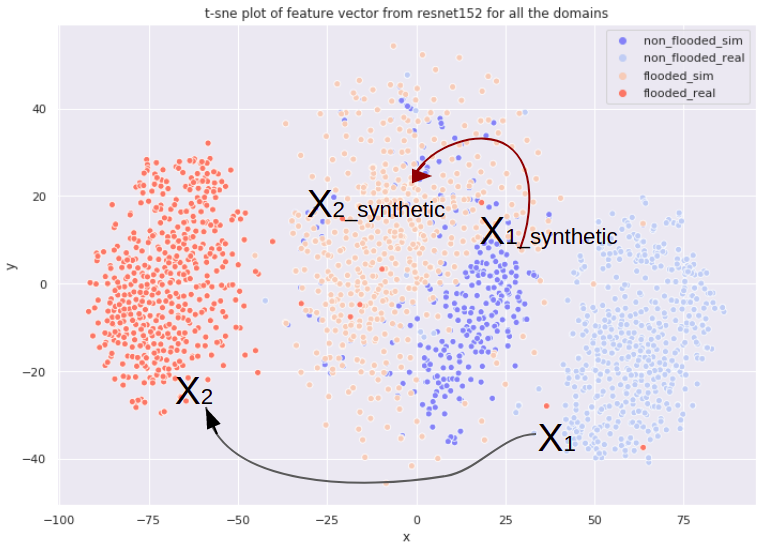
We can visualize the discrepancies between the differents domains with a T-SNE plot. Learning to flood natural images is equivalent to adapt samples from domain to domain
and we would like to help the network learn this translation with an easier task: translating from
to
. Indeed, probably because of its pairs, the gap separating the synthetic domains is smaller than for the real one. We also notice that some of the real data are mixed with the synthetic cluster, somehow a proof that the synthetic world is well imitating the real world.
We mix simulated data with their natural equivalent (synthetic flooded images with flooded images) at training time with an additional pixelwise reconstruction loss computed on the pixel that shouldn't be altered.
Where mask correspond to the region of pixels where
and
are paired, in our case, where there is no water.
Evaluating the realism of our results
We synthesized our attempt to establish an automated evaluation metric to quantify fake Image realism in the following paper . Our work consisted in adapting several existing metrics (IS,FID, KID..) and assessing them against gold standard human evaluation: HYPE. While insufficient alone to establish a human-correlated automatic evaluation metric, we believe this work begins to bridge the gap between human and automated generative evaluation procedures.
Data Mining And Annotation:
We set a goal of recovering about 1000 images in each domain meeting a number of criteria.
Flooded Houses: images should present a part of a single house or building visible and the street partially or fully covered by water.
These images have been gathered using the results of different Google Image queries focusing on North-American suburban type of houses.
Non-flooded houses are a mix of several types of images:
- Single houses with grass gathered manually from the Web.
- Street-level imagery extracted from Google StreetView API.
- Diverse street-level imagery covering a variety of weather conditions, seasons, times of day and viewpoints taken from a publicly available dataset.
Motivated by the idea that it would be easier to perform Image To Image Translation if our GAN had an idea of what the concepts of Ground and Water are, we increased the knowledge we had on the dataset by annotating pixels corresponding to Water in the Flooded Houses images and those corresponding to the Ground in Non-flooded houses images.
- 70% of the Flooded Houses were annotated using a Semantic Segmentation Network, namely DeepLab v2 trained on COCO-stuffs-164k dataset and merging some labels to output a binary mask of water.
- 30% of them have been manually annotated using LabelBox.
- 100% of the Non Flooded Houses were automatically segmented using DeepLab trained on CityScapes.



